在当今数字时代,先进的机器学习技术让篡改语音内容变得更加容易,引发了人们对语音真实性的担忧。深度伪造语音技术能够高度模仿个人语音特征,生成逼真的合成语音,这对信息真实性验证构成了严峻挑战。基于深度学习的音频合成器通常通过神经网络模拟人类发声过程,利用编码器-解码器架构生成语音。然而,真实的人类语音由复杂的声学结构和多重生物参数(如性别、年龄、健康状况等)共同决定,这些因素难以被合成器完全复现,因此它们的合成语音在词汇构成、词间过渡和情感风格上仍存在不足。在声学领域,这些特征可通过音素建模来表征——音素是语音的基本单位,其构型和过渡反映了个人的说话习惯与风格。一些研究尝试基于音素设计检测模型,但这些方法通常需要为不同数据集提取特定音素集合,耗时且泛化能力有限,同时忽视了音素序列的整体时序特征。
针对上述问题,在国家自然科学基金(项目编号:62071142)和广东省自然科学基金(项目编号:2024A1515012299)的支持下,哈尔滨工业大学(深圳)花忠云教授团队提出了一种基于音素级特征不一致性的伪造音频检测模型。该模型的整体框架如图1所示,通过聚焦音素级语音特征,有效解决了现有基于音素方法的局限性。具体而言,该方法使用特征提取器提取帧级语音特征,并使用音素识别模型识别音素,再使用音素自适应池化方法转化帧级语音特征为音素特征序列。这既保留了每个音素的个体特性,又维持了整体语句风格。随后,在相邻音素间构建边关系,并采用图注意力模块(GAT)学习音素级特征的时序依赖性。为进一步增强模型的鲁棒性,研究团队还提出了一种随机音素替换增强技术,通过动态替换音素提升训练过程中语音特征的多样性。实验结果表明,该方法在四个基准数据集上表现优异,验证了其在多种场景下的有效性。
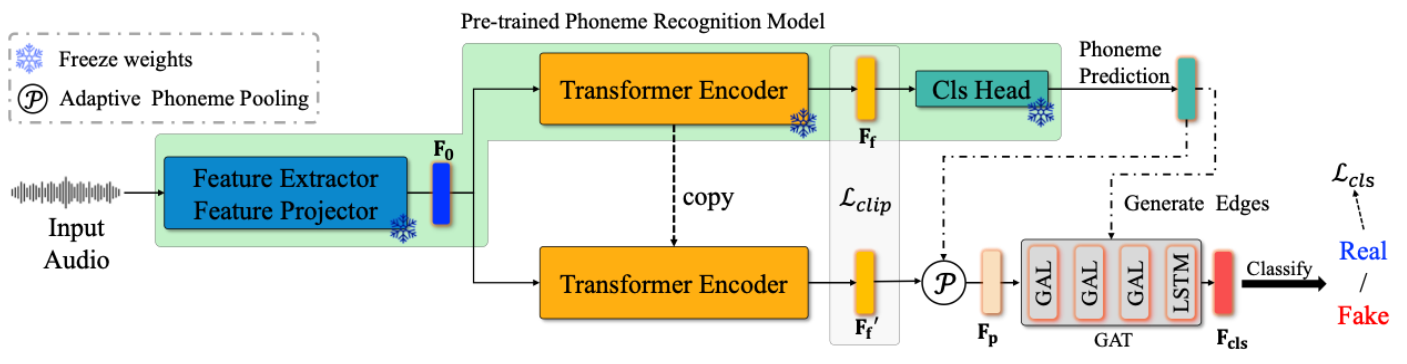
图1: 伪造音频检测模型框架
成果已发表于人工智能领域A类学术会议AAAI 2025 oral:https://ojs.aaai.org/index.php/AAAI/article/view/32093 ,并且论文源代码已公开:https://github.com/RedamancyAY/PLFD-ADD。
哈尔滨工业大学(深圳)花忠云教授团队长期从事应用密码学、人工智安全、多媒体安全等领域研究,近年来在ACM CCS,USENIX Security, ICML, CVPR, IEEE TIFS, IEEE TDSC, IEEE TC, IEEE TPDS等国际顶会议和期刊发表论文数十篇,荣获2022年,2023年及2024年科睿唯安“高被引科学家”。(审核 花忠云)
