人工智能语音合成技术(又称深度伪造语音技术)致力于生成或模仿目标人物的语音,以实现特定目的。随着语音合成与转换技术的飞速发展,深度伪造语音的质量已达到几乎以假乱真的程度。然而,这种技术的滥用可能带来严重的安全隐患,因此提高信息安全性成为亟待解决的问题。目前,许多研究者通过设计深度伪造语音检测模型来识别伪造语音。然而,现有方法大多依赖于对特定合成器特征痕迹的识别,这种方法在面对未知合成器生成的语音时表现有限,导致检测模型的泛化能力较弱。
针对这一问题,在国家自然科学基金(62071142)和国家重点研发计划(2022YFB3103500)项目的支持下,哈尔滨工业大学(深圳)花忠云教授团队提出了一种鲁棒的深度伪造语音检测方法。该方法通过特征分解学习提取与合成器无关的内容特征,作为检测的补充依据。如图1所示,该方案采用双流特征分解学习策略:合成器流在合成器标签的监督下专注于学习合成器相关特征;内容流则利用基于伪标签的监督学习方法,通过随机改变音频速度和压缩方式生成训练伪标签,从而专注于提取不受合成器影响的内容特征,并结合对抗学习技术进一步降低内容流中的合成器相关成分。最终分类结果通过对合成器特征与内容特征的拼接实现。
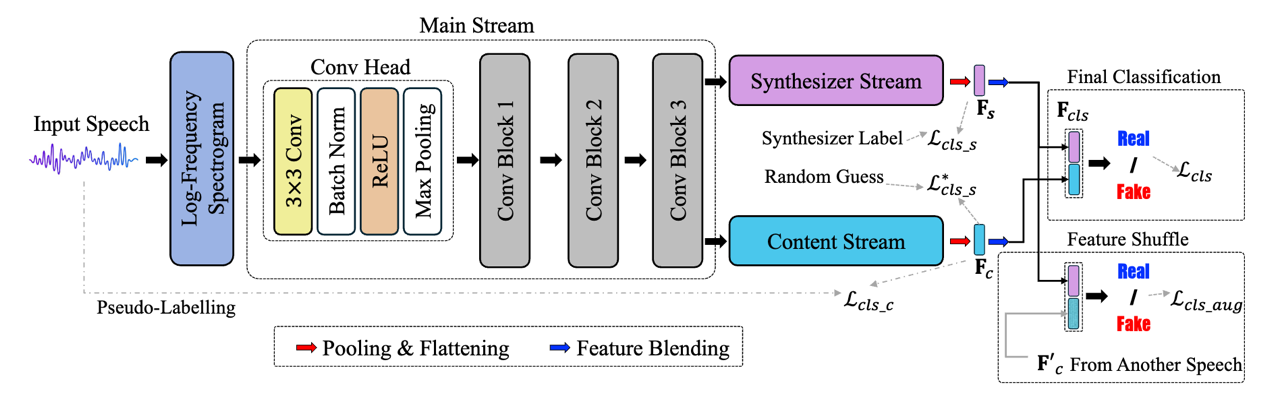
图1: 伪造音频检测模型框架
为进一步增强模型对不同合成器特性的适应能力,该方案中还提出了一种合成器特征增强策略。该策略通过随机混合真假音频中的风格特性,并对合成器特征与内容特征进行随机置换,有效提升了特征多样性,模拟了更多潜在的特征组合。实验结果表明,该方法在四个深度伪造语音基准数据集上表现出色,在跨方法、跨数据集以及跨语言等多种评估场景下均实现了鲁棒的检测性能。
成果已发表于信息安全领域A类期刊IEEE TIFS:https://ieeexplore.ieee.org/abstract/document/10806877 ,论文源代码已公开:https://github.com/RedamancyAY/RobustSpeechDetection
哈尔滨工业大学(深圳)花忠云教授团队长期从事应用密码学、人工智安全、多媒体安全等领域研究,近年来在ACM CCS,USENIX Security, ICML, CVPR, IEEE TIFS, IEEE TDSC, IEEE TC, IEEE TPDS等国际顶会议和期刊发表论文数十篇,荣获2022年,2023年及2024年科睿唯安“高被引科学家”。(审核 花忠云)
