近年来,专注于代码智能化领域的大语言模型,如CodeQwen和DeepSeek-Coder展现出在理解和生成代码方面的巨大潜力。然而,将这些模型应用于实际环境仍面临诸多挑战。专用大模型虽然可通过API使用,但其高昂的使用成本,限制了个人和中小型组织的应用;开源大模型虽更易获取且具有较高灵活性,却也存在各自短板。超大规模模型(如70B级模型)在本地部署时对算力资源要求极高,而轻量级大模型(如7B级模型)虽资源占用较低,却常在下游任务中表现不佳。这些问题凸显了对易访问、高效且轻量化的大模型的迫切需求。
在国家自然科学基金(批准号:62472126)等项目的支持下,哈尔滨工业大学(深圳)高翠芸教授团队提出“自节奏知识蒸馏”(Self-Paced knOwledge DistillAtion,SODA)框架,通过迭代式知识迁移,将70B级教师模型的编程能力有效注入7B级学生模型,为业界和学界带来可落地的轻量级大模型代码生成方案。相关成果已被领域顶级会议 ACM International Conference on the Foundations of Software Engineering (FSE2025,CCF A类会议)正式录用。
SODA框架在单次蒸馏循环中依次执行三大阶段:首先,通过“正确-错误对比学习”同时教授正确编程范式与典型错误模式,使学生模型具备“会写也会改”的能力;接着,借助微调后的CodeLlama-7B评分器与多语言执行沙箱对学生测验结果进行评估,精准识别“易-中-难”问题,为后续学习提供针对性反馈;最后,依据难度分层动态生成新问题,形成“提出-反馈-再学习”的自闭环迭代机制,使学生模型能力持续攀升。基于SODA训练得到的7B级轻量模型SodaCoder-DS-6.7B,在七种编程语言上的平均 通过率(Pass@1)达到66.5,不仅超越16B以下的15个公开模型,更反超Llama3-70B (65.0)与ChatGPT(61.3)。该工作不仅显著降低了部署成本(SodaCoder-DS原生推理速度约为Llama3-70B的26倍),还为代码审查、缺陷修复等错误敏感型场景提供了天然优势,显示出广阔的产业应用潜力。
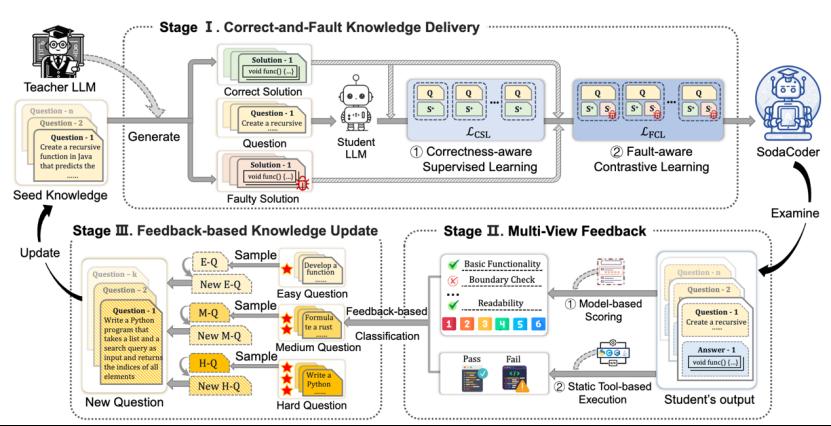
图1 提出的SODA框架

图2 多视角反馈评估案例研究
哈尔滨工业大学(深圳)高翠芸教授团队主要从事于软件分析、软件知识库挖掘、软件安全、代码自动化生成、元宇宙软件等,做有工业应用前景的工作。已在国际顶级会议和期刊(ICSE,ASE,FSE,TSE,WWW等)发表100+篇论文。荣获2025年CCF-A类会议ICSE杰出论文奖、2024年CCF-A类会议ICSE杰出论文奖、2024年CCF-A类会议ICSE企业竞赛通道最佳论文奖等多个奖项。(审核 廖清)
