随着大语言模型(LLM)在软件工程领域的深入应用,如何规模化地构建可执行的代码数据,已成为提升模型代码理解、生成和修复能力的关键瓶颈。为解决这一问题,研究人员需要为海量的代码仓库配置复杂的运行环境以进行测试和数据收集,但传统方法依赖于专家手动操作,这一过程不仅耗时、耗力且高度依赖领域知识,极大地限制了可执行代码数据的生产效率和规模,导致该领域缺乏高质量的基准和训练数据。
在国家自然科学基金(批准号:62472126)等项目的支持下,哈尔滨工业大学(深圳)高翠芸教授团队提出了一种名为Repo2Run的、基于大语言模型的自动化智能体框架,旨在规模化地解决代码仓库可执行环境的构建难题。该框架创新性地设计了内部与外部双重Docker环境的交互架构,使得智能体不仅能执行安装、测试等常规操作,还能通过外部环境实现对底层系统(如更换基础镜像版本)的控制,从而解决传统方法难以处理的复杂环境配置失败问题。此外,Repo2Run采用“构建-记录”两阶段策略,首先在交互式的“构建”阶段,通过试错和智能回滚,探索出一条完整的、可成功执行测试的命令序列;然后在“记录”阶段,将这条经过验证的命令序列确定性地合成为一个被验证可运行的Dockerfile,从根本上保证了输出Dockerfile的可靠性。
为验证方法的有效性,团队构建了一个包含420个带有单元测试的真实Python代码仓库的基准测试集。研究表明,Repo2Run在环境构建任务上取得了86.0%的成功率,显著优于如SWE-agent等现有主流方法。成果被人工智能领域的国际顶级学术会议NeurIPS 2025 (Conference on Neural Information Processing Systems)录用,并被接收为Spotlight论文。NeurIPS是中国计算机学会(CCF)推荐的A类会议,也是全球最负盛名、最具影响力的人工智能和机器学习领域的学术会议之一。Spotlight论文是在海量投稿中经过严格筛选,被认为具有高度创新性和重要研究价值的亮眼工作,今年的录取率为3.19%(688/21,575)。
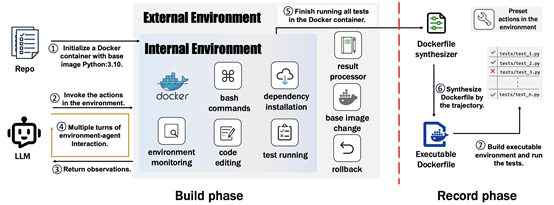
图1 Repo2Run框架的整体架构图

图2 Repo2Run的Dockerfile转换规则
哈尔滨工业大学(深圳)高翠芸教授团队主要从事于软件分析、软件知识库挖掘、软件安全、代码自动化生成、元宇宙软件等,做有工业应用前景的工作。已在国际顶级会议和期刊(ICSE,ASE,FSE,NeurIPS,TSE,WWW等)发表100+篇论文。荣获2025年CCF-A类会议ICSE杰出论文奖、2024年CCF-A类会议ICSE杰出论文奖、2024年CCF-A类会议ICSE企业竞赛通道最佳论文奖等多个奖项。
(审核 高翠芸)
